- 13 avr. 2025
Clean Architecture MVVM en Swift
Introduction
Quand on débute (ou même quand on a déjà un peu d’expérience), il est tentant de tout mettre dans les vues ou les ViewModels pour aller vite. Ça marche… au début. Et puis un jour, votre projet grandit. Les fonctionnalités s’empilent, les bugs aussi, et vous vous retrouvez avec du code spaghetti impossible à tester, difficile à maintenir, et encore plus difficile à faire évoluer.
C’est là que la Clean Architecture entre en jeu.
Elle vous permet de structurer votre code de façon claire, modulaire et évolutive, même pour les projets SwiftUI.
Dans cet article, vous allez découvrir :
Ce qu’est concrètement la Clean Architecture (et ce qu’elle n’est pas),
Quelles sont les différentes couches (Domain, Data, Presentation…),
Le rôle précis de chaque composant : Use Cases, Repositories, DataSources, etc.
Comment tout cela s’applique en pratique dans un projet SwiftUI,
Et pourquoi cette approche va littéralement vous simplifier la vie.
Notre objectif, c’est de vous aider à comprendre les bases, étape par étape, même si vous êtes encore novice. Vous aurez bientôt une vision claire de ce qu’est un code propre, testable, et organisé.
Pour suivre cet article, nous supposerons que vous avez déjà de bonnes connaissances en développement iOS. Vous avez déjà développé vos premières applications mais vous faites face à des difficultés pour organiser votre projet et votre code.
Les 3 couches d’une application
La Clean Architecture en SwiftUI peut s’organiser en 3 couches différentes. Voyez cette organisation comme un oignon 🧅 (oui oui, un oignon). La couche la plus externe, celle que l’on peut voir, c’est l’écran de votre application, qu’on appelle la Vue.
La couche la plus interne (le coeur de l’oignon), c’es votre base de données. C’est là que sont stockées toutes vos données sur un serveur par exemple.
Le but de la Clean Architecture, ça va être de traverses les différentes couches entre la plus externe, et la plus interne, en respectant différentes étapes qui nous permettront d’organiser notre code proprement.
Voici les 3 couches que nous allons présenter dans cet article, dans lesquelles se répartissent 7 composantes d’une application :
La couche présentation (Presentation Layer)
La couche domaine (Domain Layer)
La couche données (Data Layer)
Pas de panique ! Nous allons détailler chacune des couches avec de nombreux exemples.
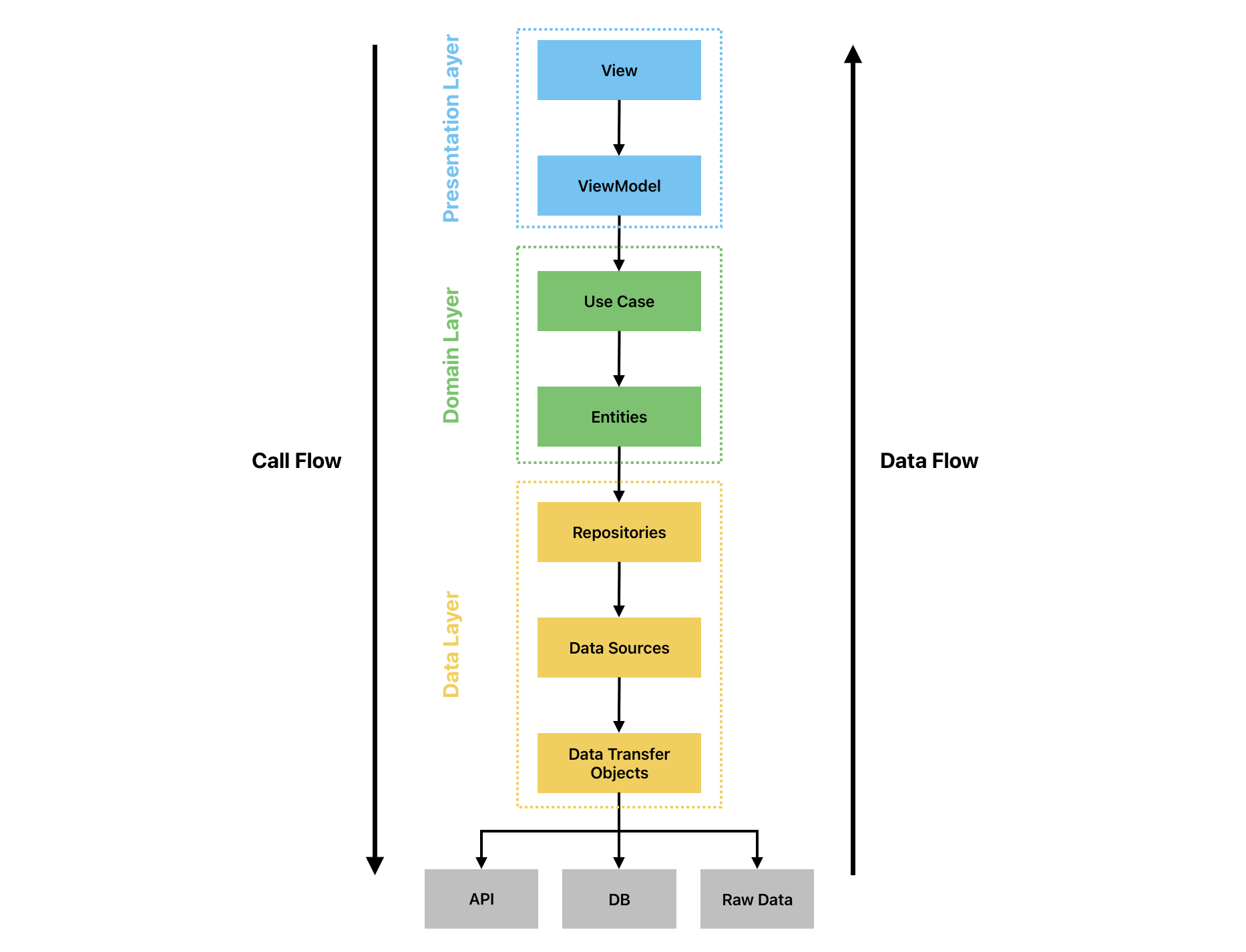
Pour comprendre l’utilité des différentes couches, nous allons retracer toutes les étapes que traversent les données, en partant de la base de données (en bas du schéma) à l’affichage de ces mêmes données sur l’écran (en haut du schéma). Pour le cheminement inverse (de l’interaction utilisateur jusqu’à la modification de la base de données) il suffira de parcourir les différentes couches en sens inverse.
Nous allons nous baser majoritairement sur l’API PokéApi qui est gratuite, et dont vous pourrez vous servir pour recopier vous-mêmes les exemples.
En attendant, nous pouvons déjà créer les 4 dossiers suivants :
Core
Data
Domain
Presentation
Le 4ème dossier Core permet de stocker tous les fichiers tiers utiles au développement de l’application. C’est un peu comme une boite à outils partagée. On peut y stocker : les clés API, les extensions, les types génériques, etc.
Nous remplirons ces différents dossiers tout au long de ce tutoriel.
La couche Data
Commençons par étudier la couche Data : la plus proche de la base de données. La première chose à comprendre, c’est que les données stockées sur la base de données auront rarement la même organisation que dans votre application.
Voici l’exemple d’un livre stocké dans la base de données :
{
"book_id": "abc123",
"book_title": "Clean Architecture Explained",
"pages_total": 320,
"pages_read": 120,
"created_at": "2024-01-01T10:15:00Z"
}
Et son objet correspondant en Swift :
struct Book {
let id: String
let title: String
let totalPages: Int
let pagesRead: Int
let createdAt: Date
var progress: Double {
guard totalPages > 0 else { return 0 }
return Double(pagesRead) / Double(totalPages)
}
}
On remarque que certaines propriétés n’ont pas le même nom (book_id et id par exemple). De plus, certaines informations ne sont stockées que dans l’objet Swift (la progression de l’utilisateur par exemple).
Dans cet exemple, les données sur la base de données sont stockées au format JSON. Or, le langage Swift ne comprend pas le JSON. Il faut donc transformer les données récoltées sur la base en Swift. C’est le rôle du DTO.

Les Data Transfer Objects (DATA)
Le premier composant de la couche Data, c’est le Data Transfer Object. C’est une objet (souvent une structure, mais cela peut aussi être une énumération ou une classe) qui recopie l’organisation des données sur la base.
Sa construction est simple :
chaque clé JSON sera représentée par une propriété
chaque propriété aura le même type que sur la base
Il suffit donc de regarder l’organisation de la base de données ou la documentation de l’API pour créer son DTO. Si, par exemple, on souhaite récolter des informations concernant un Pokémon : d’après la documentation, on peut appeler l’URL suivant :
https://pokeapi.co/api/v2/pokemon/{id or name}/
Les données sont alors organisées de cette manière :

Il suffit ensuite de piocher dans les informations qu’on souhaite récupérer dans notre app. Si, par exemple, on souhaite récupérer l’identifiant, le nom, le poids et la taille, on peut créer l’objet suivant dans le dossiers Data/DTO :
struct PokemonDTO {
let id: Int
let name: String
let weight: Int
let height: Int
}
Remarque : il est primordial que toutes les propriétés aient le même type que les données stockées sur le serveur, car nous allons utiliser cette structure pour décoder les données.
Comme l’objet PokemonDTO servira pour le décodage, nous devons le rendre encodable et décodable :
struct PokemonDTO: Codable {
let id: Int
let name: String
let weight: Int
let height: Int
}
Si, dans notre app, on souhaite également récolter l’ensemble des Pokémons du Pokédex (voir un exemple ici) on peut également créer l’objet suivant, toujours dans Data/DTO :
struct PokemonResultDTO: Decodable {
let name: String
let url: String
}
struct PokemonListDTO: Decodable {
let count: Int
let next: String
let results: [PokemonResultDTO]
}
Grâce à ces deux objets, nous allons pouvoir récupérer tous les Pokémons disponibles sur la base de données. Mais cette récupération (via un appel API par exemple) n’est pas du tout le rôle du DTO. Le DTO est un objet statique qui ne fait que représenter la structure en base.
Pour récupérer ces données, nous allons utiliser le second composant de la couche Data : le Data Source.

Les DataSources (DATA)
Le DataSource est responsable d’accéder directement aux données brutes, que ce soit depuis une API, une base locale ou un fichier.
Il connaît les détails techniques de récupération ou de sauvegarde des données (URL, requêtes, requêtes Core Data, etc.).
Le DataSource ne contient aucune logique métier : il exécute simplement ce qu’on lui demande de façon technique.
Bonne pratique : il est conseillé de créer plusieurs Data Sources pour garder un code propre. Il existe plusieurs écoles : un Data Source par type (ex : PokemonDataSource, AttackDataSource, etc) ou un DataSource par source de données (ex : FirebaseDataSource, AWSDataSource, LocalDataSource, etc).
Le top du top, c’est de créer un DataSource par source ET par type (ex : PokemonFirebaseDataSource, PokemonLocalDataSource, etc).
Mais si votre projet reste petit, vous pouvez vous contenter d’un seul DataSource par Type ou par source de données.
Dans notre exemple, nous allons créer un DataSource pour les pokémons stockés sur API dans Data/DataSource :
enum PokemonDataSourceError: Error {
case invalidURL
case invalidReponse
case parsingError
}
class PokemonAPIDataSource {
func getPokemons(offset: Int, limit: Int) async throws -> PokemonListDTO {
guard let url = URL(string: "<https://pokeapi.co/api/v2/pokemon/?limit=\(limit)&offset=\(offset)>") else {
throw PokemonDataSourceError.invalidURL
}
let (data, response) = try await URLSession.shared.data(from: url)
guard let response = response as? HTTPURLResponse, response.statusCode == 200 else {
throw PokemonDataSourceError.invalidReponse
}
do {
let list = try JSONDecoder().decode(PokemonListDTO.self, from: data)
return list
} catch {
throw PokemonDataSourceError.parsingError
}
}
}
Dans cet exemple, nous avons créé une fonction pour récupérer la liste de tous les pokémons, mais nous pourrions aussi mettre d’autres fonctions telles que getPokemon(by id: Int) ou toute autre méthode qui récupère des Pokémons sur l’API.
Attention ! Les méthodes du DataSource ne doivent renvoyer que des DTOs, rien d’autre !
func fetchPokemons() async throws -> [Pokemon] // ❌ Interdit
func fetchPokemons() async throws -> [PokemonDTO] // ✅ Valide
On peut maintenant tester notre DataSource dans ContentView (⚠️ Attention, on a le droit, juste parce qu’on est entre nous…)
struct ContentView: View {
var body: some View {
Button {
Task {
let dataSource = PokemonAPIDataSource()
do {
let list = try await dataSource.getPokemons(offset: 0, limit: 20)
print(list)
} catch {
print(error)
}
}
} label: {
Text("Test Data Source")
}
}
}
On récupère bien la liste des 20 premiers Pokémons :
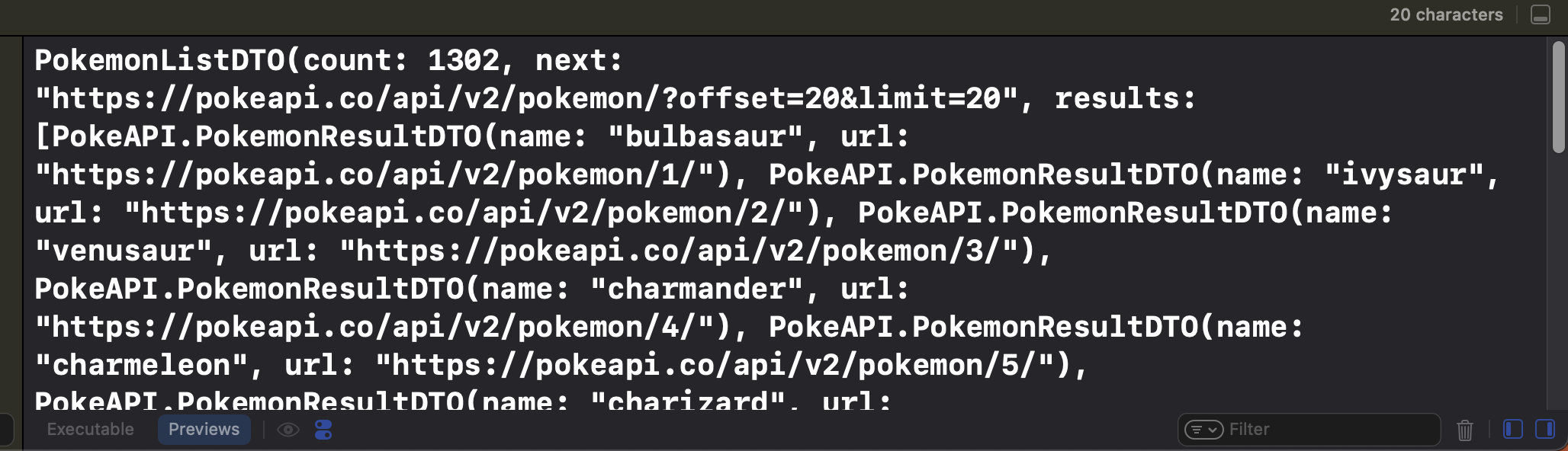
Maintenant que nous avons récupéré la liste des pokémons, nous faisons face à un problème : nous n’avons qu’une partie des informations. Nous l’avons que le nom et l’identifiant du Pokémon. Mais dans notre exemple, on souhaite également avoir accès à d’autres données telles que le poids et la taille.
On peut donc ajouter une deuxième méthode dans le DataSource pour faire un deuxième appel API et récupérer le poids et la taille :
func getPokemonDetails(id: String) async throws -> PokemonDTO {
guard let url = URL(string: "<https://pokeapi.co/api/v2/pokemon/\(id)/>") else {
throw PokemonDataSourceError.invalidURL
}
let (data, response) = try await URLSession.shared.data(from: url)
guard let response = response as? HTTPURLResponse, response.statusCode == 200 else {
throw PokemonDataSourceError.invalidReponse
}
do {
let pokemon = try JSONDecoder().decode(PokemonDTO.self, from: data)
return pokemon
} catch {
throw PokemonDataSourceError.parsingError
}
}
Mais maintenant, que faire avec ces deux types d’informations ? D’un côté, on a la liste des pokémons, mais avec uniquement les noms. Et de l’autre, un a les détails d’un Pokémon, mais pour un seul Pokémon à la fois.
Pour regrouper ces informations, on aura besoin de deux choses : un Mapper et un Repository. Ces deux objets vont créer ce qu’on appelle une entité, qui contiendra toutes les informations nécessaires (l’identifiant, le poids, la taille, etc).

Les Entities (DOMAIN)
Une entité représente un objet métier essentiel dans votre application. C’est une structure qui contient les données importantes (comme un Pokemon, un Livre, un Utilisateur) et parfois des règles simples liées à ces données.
Les entités sont définies dans la couche Domain, elles sont indépendantes de l’interface utilisateur ou des sources de données.
On les utilise pour décrire ce que manipule réellement votre application, peu importe d’où viennent les données ou comment elles sont affichées.
Dans notre exemple, on peut tout simplement créer une entité : Pokemon dans le dossier Domain/Entity.
struct Pokemon: Identifiable {
let id = UUID()
let name: String
let url: String
let weight: Int
let height: Int
var imageUrl: String {
"<https://raw.githubusercontent.com/PokeAPI/sprites/master/sprites/pokemon/other/official-artwork/\>(url.split(separator: "/").last ?? "1").png"
}
}
Nous savons maintenant que l’application (et plus précisément les vues, dont on parlera plus tard) utilisera des objets de type Pokemon. Or, nous, nous n’avons que des objets de type PokemonDTO. Nous allons donc devoir effectuer une transformation.
Cette séparation entre le DTO et l’entité permet de découpler le back-end du front-end. Mais maintenant : comment faire pour transformer des DTOs (fournis par l’API) en entités (utilisés par l’application) ? C’est le rôle des Mappers.
Les Mappers (DATA)
Un Mapper est une petite pièce de code qui sert à transformer des données d’un format à un autre. Par exemple, il permet de convertir un objet brut reçu d’une API (appelé DTO) en une entité métier propre à votre application, ou l’inverse.
C’est une étape clé pour séparer la structure des données techniques (issues d’une API, d’une base locale…) de la logique métier de votre app.
On place généralement les Mappers dans la couche Data, car ils dépendent des formats utilisés par les sources de données.
On peut donc créer une class PokemonMapper dans le dossier Data/Mapper :
class PokemonMapper {
static func map(pokemonResultDTO: PokemonResultDTO, pokemonDTO: PokemonDTO) -> Pokemon {
return Pokemon(
name: pokemonDTO.name,
url: pokemonResultDTO.url,
weight: pokemonDTO.weight,
height: pokemonDTO.height
)
}
}
Ici, le mapper contient une seule méthode map(: PokemonResultDTO, : PokemonDTO) -> Pokemon qui permet de transformer un objet de la couche Data, en entité de la couche Domain.
On peut y ajouter plusieurs méthodes si on doit mapper plusieurs types de données.
Maintenant que nous savons comment transformer nos DTOs en entités, nous allons pouvoir utiliser le mapper dans la prochaine composante de la couche Data : le Repository.

Les Repositories (DATA)
Un Repository est une couche intermédiaire entre la logique métier (Use Cases) et les sources de données (API, base locale, etc.). Il sert à récupérer ou enregistrer des données, tout en cachant les détails techniques de leur provenance.
Grâce au Repository, le reste de l’application n’a pas besoin de savoir si les données viennent d’une API, d’une base locale ou d’ailleurs. Il fournit simplement des entités prêtes à l’emploi (pas des DTO), ce qui rend le code plus clair, modulaire et facile à tester.
Dans notre exemple, le Repository va justement nous permettre de récolter toutes les informations dont on a besoin à droite à gauche (via le DataSource) et les mettre en forme pour créer un tableau de Pokémons ([Pokemon]) que nous pourrons utiliser directement dans la vue.
Remarque : La bonne pratique, c’est de créer un Repository par type ou par fonctionnalité. Ici, on peut créer un Repository pour les Pokémons, un pour les attaques, un pour les baies, etc.
Dans le dossier Data/Repositories, on peut créer une nouvelle classe :
class PokemonRepository {
let pokemonDataSource = PokemonAPIDataSource()
func getPokemons(offset: Int, limit: Int) async throws -> [Pokemon] {
do {
// Récupération de la liste des pokémons
let pokemonListDTO = try await pokemonDataSource.getPokemons(offset: offset, limit: limit)
var pokemons: [Pokemon] = []
// Pour chaque pokémon trouvé, récupération des détails (poids, taille, etc)
for pokemonResultDTO in pokemonListDTO.results {
let pokemonID = pokemonResultDTO.url.split(separator: "/").last ?? "1"
let pokemonDTO = try await pokemonDataSource.getPokemonDetails(id: String(pokemonID))
let pokemon = PokemonMapper.map(pokemonResultDTO: pokemonResultDTO, pokemonDTO: pokemonDTO)
pokemons.append(pokemon)
}
return pokemons
} catch {
throw error
}
}
}
Encore une fois, on peut tester notre Repository dans ContentView (⚠️ Attention ! Ceci est encore une fois formellement interdit, mais c’est juste parce qu’on est entre nous).
struct ContentView: View {
var body: some View {
Button {
Task {
let repository = PokemonRepository()
do {
let list = try await repository.getPokemons(offset: 0, limit: 20)
print(list)
} catch {
print(error)
}
}
} label: {
Text("Test Repository")
}
}
}
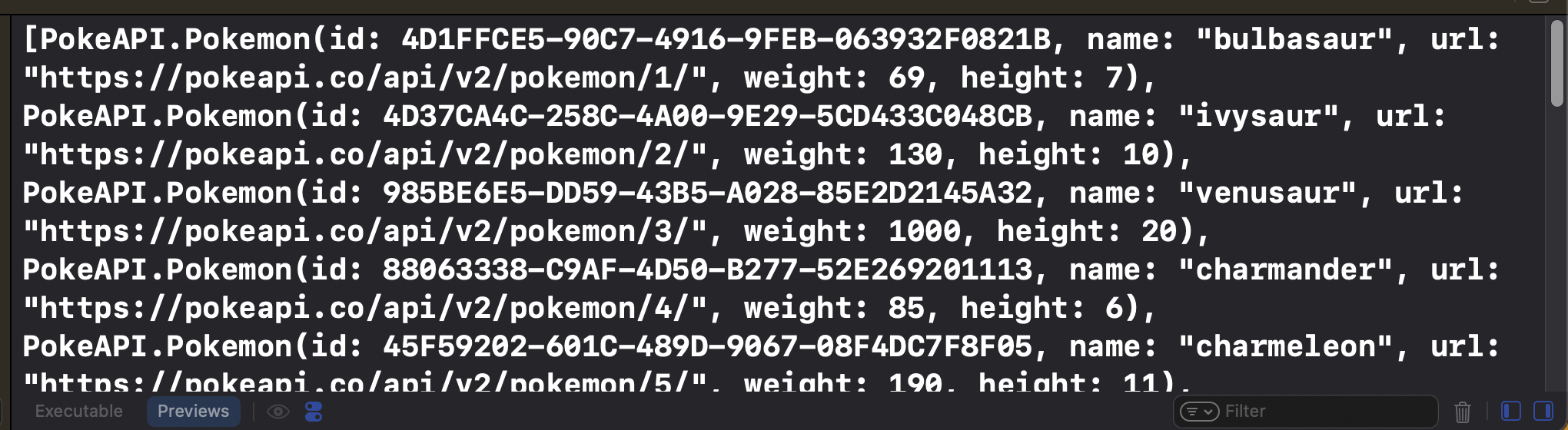
Nous savons donc maintenant comment récupérer l’ensemble des Pokémons (sous forme de tableau [Pokemon]). Le reste de notre application ne devra donc recevoir qu’un tableau de ce type, sans se soucier de la logique qui a été utilisée pour récupérer ces informations.
Le Repository ne permet donc que d’effectuer des tâches techniques, mais ne se soucie pas de la logique métier. Nous devons donc introduire une nouvelle couche : la couche UseCases.

Les UseCases (DOMAIN)
Un Use Case représente une action métier précise que l’utilisateur peut effectuer dans l’application, comme récupérer une liste de Pokémon, ajouter un livre aux favoris, ou se connecter. Il contient la logique métier propre à cette action : tri, filtrage, validation, etc.
Il s’appuie sur les Repositories pour obtenir ou enregistrer les données, sans jamais gérer les détails techniques (API, base de données…).
Le Use Case permet ainsi de centraliser la logique métier, de la rendre réutilisable, testable, et totalement indépendante de l’interface utilisateur.
Mais alors… Quelle est la différence avec le Repository ?
Le UseCase décrit ce que l’utilisateur veut faire.
Le repository fournit les données nécessaires.
Le UseCase Contient la logique métier (filtres, tris, etc).
Le Repository Gère l’accès aux sources de données.
Dans notre exemple, si nous voulions trier les Pokemons (par types par exemple), ça serait le rôle du UseCase.
Nous pouvons donc créer une nouvelle classe dans le dossier Domain/UseCases. Chaque UseCase représente une action concrète réalisée par l’utilisateur :
class GetAllPokemonsUseCase {
let repository = PokemonRepository()
func execute(offset: Int, limit: Int) async throws -> [Pokemon] {
return try await repository.getPokemons(offset: offset, limit: limit)
}
}
Chaque classe représente une action. Voici quelques exemples :
GetAllPokemonsUseCaseGetAllAttacksUseCaseSavePokemonAsFavouriteUseCaseCapturePokemonUseCaseetc
Chaque classe de type UseCase ne contient qu’une seule méthode execute (qui peut prendre des paramètres).
Dans notre exemple, la méthode execute le fait qu’un appel à repository.getPokemons. Mais si un tri ou un filtre devait être fait, c’est dans la méthode execute qu’il le serait.
Maintenant, nous savons récupérer toutes les données (potentiellement triées, filtrées, organisées, et mises en forme comme on le souhaite). On va pouvoir les transmettre à la dernière couche de notre application : la vue. Mais les vues ne doivent pas communiquer directement avec la couche UseCase.
Pour faire le lien entre la couche UseCase et la couche View, nous allons introduire la couche ViewModel.

Les ViewModels (PRESENTATION)
Le ViewModel appartient à la couche Présentation. Il sert d’intermédiaire entre la vue (SwiftUI) et la logique métier (Use Cases).
Son rôle, c’est :
préparer les données à afficher dans l’interface,
réagir aux actions de l’utilisateur (tap, scroll, refresh…),
appeler les Use Cases pour récupérer ou modifier les données.
Toutes les actions déclenchées par l’utilisateur (tap sur un bouton, scroll, etc) ou par un autre évènement (notification, changement d’état de l’app, mise à jour du serveur, etc) passeront forcément par le ViewModel.
Le ViewModel ne contient ni logique métier complexe, ni logique technique (pas d’appel API direct), et ne connaît jamais les DataSources ou Repositories. Il se contente juste d’afficher bêtement les informations reçues via le UseCase, sur la vue.
Le ViewModel doit donc être étroitement lié à la vue. Pour construire un ViewModel, on doit d’abord lister toutes les données dont on aura besoin pour construire la vue.
Supposons que l’on souhaite afficher la liste des Pokemons, avec un indicateur de chargement et un message d’erreur. On aura donc besoin de :
La liste des Pokemons à afficher (
[Pokemon])Un indicateur de chargement (
Bool)Un message d’erreur (
String?)
Dans le dossier Presentation/ViewModels, on peut créer un nouveau fichier :
@MainActor
class PokemonListViewModel: ObservableObject {
@Published var pokemons: [Pokemon] = []
@Published var isLoading: Bool = false
@Published var errorMessage: String? = nil
}
Dans le ViewModel, on ajoutera toutes les méthodes dont aura besoin la vue, comme par exemple :
Charges les Pokemons
Ajouter un Pokemon aux favoris
Supprimer un Pokemon de sa liste
etc
Toutes ces actions passeront forcément par un ou plusieurs UseCase. Le ViewModel ne doit communiquer qu’avec la couche UseCase, et surtout pas avec le Repository ni le DataSource.
@MainActor
class PokemonListViewModel: ObservableObject {
@Published var pokemons: [Pokemon] = []
@Published var isLoading: Bool = false
@Published var errorMessage: String? = nil
private let getAllPokemonsUseCase = GetAllPokemonsUseCase()
func loadPokemons(offset: Int = 0, limit: Int = 20) async {
isLoading = true
errorMessage = nil
do {
let result = try await getAllPokemonsUseCase.execute(offset: offset, limit: limit)
pokemons = result
} catch {
errorMessage = "Une erreur est survenue : \(error.localizedDescription)"
}
isLoading = false
}
}
Ainsi, il ne nous reste plus qu’à utiliser ce modèle observable dans notre vue et d’appeler la méthode loadPokemons.

Les Views (PRESENTATION)
La couche Vue fait partie de la couche Présentation. Son rôle est d’afficher les données fournies par le ViewModel et de réagir aux interactions de l’utilisateur (tap, scroll, bouton, etc.).
Elle ne contient aucune logique métier, ni logique technique. Elle se contente de présenter l’état actuel de l’interface, et de notifier le ViewModel en cas d’action.
Chaque vue doit avoir un ViewModel associé. On utilisera donc la même convention de nommage : la vue [ViewName] avec son ViewModel [ViewName]Model.
Voici un exemple dans le dossier Presentation/Views :
struct PokemonListView: View {
@StateObject var viewModel = PokemonListViewModel()
var body: some View {
NavigationView {
Group {
if viewModel.isLoading {
ProgressView("Chargement...")
} else if let error = viewModel.errorMessage {
Text(error)
.foregroundColor(.red)
.multilineTextAlignment(.center)
.padding()
} else {
List(viewModel.pokemons) { pokemon in
HStack {
AsyncImage(url: URL(string: pokemon.imageUrl)) { image in
image
.resizable()
.scaledToFit()
.frame(width: 60, height: 60)
} placeholder: {
ProgressView()
}
VStack(alignment: .leading) {
Text(pokemon.name.capitalized)
.font(.headline)
Text("Taille : \(pokemon.height), Poids : \(pokemon.weight)")
.font(.subheadline)
.foregroundColor(.gray)
}
}
}
}
}
.navigationTitle("Pokémons")
.task {
await viewModel.loadPokemons()
}
}
}
}
#Preview {
PokemonListView()
}

On récupère donc la liste des Pokemons directement dans la vue grâce au ViewModel.
Conclusion
Vous l’aurez compris : adopter la Clean Architecture dans un projet iOS n’est pas un simple choix de structure, c’est une démarche volontaire pour rendre votre code plus lisible, plus maintenable, plus testable, et surtout plus évolutif dans le temps.
Tout au long de cet article, nous avons retracé le chemin complet qu’empruntent les données dans une application bien organisée :
depuis leur récupération brute via un DataSource,
leur transformation via un Mapper,
leur regroupement au sein d’un Repository,
leur traitement par un Use Case,
leur affichage final dans une Vue, via un ViewModel.
Chacune de ces couches a un rôle précis, et le respect de leurs responsabilités respectives est la clé pour construire des applications robustes et professionnelles. En segmentant votre code, vous facilitez les évolutions futures, le travail en équipe, et vous préparez votre projet à une échelle plus ambitieuse.
Évidemment, cette organisation peut paraître lourde au premier abord, surtout sur des petits projets. Mais elle devient rapidement un atout majeur dès que votre application grandit — ou dès que vous devez maintenir du code dans la durée.
✅ Un DataSource ne fait que récupérer des données.
✅ Un Repository fournit des entités, sans savoir comment elles sont obtenues.
✅ Un Use Case applique une logique métier claire.
✅ Un ViewModel orchestre l’affichage.
✅ Une Vue se contente de présenter les données à l’utilisateur.
Si vous appliquez ces principes dès aujourd’hui, vous poserez les bases d’un code professionnel, que vous soyez seul ou en équipe, sur un projet simple ou complexe. Et surtout : vous gagnerez en sérénité, car chaque partie de votre code sera prévisible, isolée, et facilement testable.